Thanks to Mike Wilson, ipython-sql now supports bind variables!
In [12]: name = 'Countess'
In [13]: %sql select description from character where charname = :name
Out[13]: [(u'mother to Bertram',)]
Thanks to Mike Wilson, ipython-sql now supports bind variables!
In [12]: name = 'Countess'
In [13]: %sql select description from character where charname = :name
Out[13]: [(u'mother to Bertram',)]
 stars (of 5)
stars (of 5)
Packt Publishing recently asked if I could review their new title, Learning IPython for Interactive Computing and Data Visualization. (I got the e-book free for doing the review, but they don't put any conditions on what I say about it.) I don't often do reviews like that, but I couldn't pass one this up because I'm so excited about the IPython Notebook.
It's a mini title, but it does contain a lot of information I was very pleased to see. First and foremost, this is the first book to focus on the IPython Notebook. That's huge. Also:
So what don't I like? Well, I wish for more. It's not fair to ask for more bulk in a small book that was brought to market swiftly, but I can wish for a more forward-looking, imaginative treatment. The IPython Notebook is ready to go far beyond IPython's traditional core usership in the SciPy community, but this book doesn't really make that pitch. It only touches lightly on how easily and beautifully IPython can replace shell scripting. It doesn't get much into the unexplored possibilities that IPython Notebook's rich display capabilities open up. (I'm thinking of IPython Blocks as a great example of things we can do with IPython Notebook that we never imagined at first glance). This book is a good introduction to IPython's uses as traditionally understood, but it's not the manifesto for the upcoming IPython Notebook Revolution.
The power of hybrid documentation/programs for learning and individual and group productivity is one more of IPython Notebook's emerging possibilities that this book only mentions in passing, and passes up a great chance to demonstrate. The sample code is downloadable as IPython Notebook .ipynb files, but the bare code is alone in the cells, with no use of Markdown cells to annotate or clarify. Perhaps this is just because Packt was afraid that more complete Notebook files would be pirated, but it's a shame.
Overall, this is a short book that achieves its modest goal: a technical introduction to IPython in its traditional uses. You should get it, because IPython Notebook is too important to sit around waiting for the ultimate book - you should be using the Notebook today. But save space on your bookshelf for future books, because there's much more to be said on the topic, some of which hasn't even been imagined yet.
This hReview brought to you by the hReview Creator.
When I upgraded from Xubuntu 12.10 to 13.04 today, all my existing Python virtualenvs broke! Fortunately, they're just virtualenvs and easy to replace (that's kind of the point). But don't panic if you start seeing these.
$ ipython Traceback (most recent call last): File "/home/catherine/ve/e2/bin/ipython", line 5, infrom pkg_resources import load_entry_point File "build/bdist.linux-i686/egg/pkg_resources.py", line 16, in File "/home/catherine/ve/e2/lib/python2.7/re.py", line 105, in import sre_compile File "/home/catherine/ve/e2/lib/python2.7/sre_compile.py", line 14, in import sre_parse File "/home/catherine/ve/e2/lib/python2.7/sre_parse.py", line 17, in from sre_constants import * File "/home/catherine/ve/e2/lib/python2.7/sre_constants.py", line 18, in from _sre import MAXREPEAT ImportError: cannot import name MAXREPEAT
Apparently Python 2.7.4 introduces _sre.MAXREPEAT. Here it is in my (new) system Python, 2.7.4:
Python 2.7.4 (default, Apr 19 2013, 18:28:01) [GCC 4.7.3] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import _sre >>> _sre.MAXREPEAT 4294967295L
... but the virtualenvs I created before the upgrade still use Python 2.7.3
Python 2.7.3 (default, Sep 26 2012, 21:51:14) [GCC 4.7.2] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import _sre >>> _sre.MAXREPEAT Traceback (most recent call last): File "", line 1, in AttributeError: 'module' object has no attribute 'MAXREPEAT'
If I were a deeper hacker I'd try to figure out why code running within my old virtualenvs is trying to access a 2.7.4-only attribute, or what's the most efficient way to recover my old virtualenvs. But I'll settle for recognizing the problem and spinning up new virtualenvs instead. That fixes the problem.
I know... I could have avoided this problem by using Python 3! I've got code that depends on fabric, though, which still isn't available for 3.
Have you responded yet to PyOhio's Call For Proposals (due date: June 1)? You should. Here's why.
Perfect. Because the great curse of expert teachers is that they can forget what it was like to be a beginner. So dive into something you want to learn, take careful notes as you go about what confused you and how you resolved it, and you'll blaze a trail that you can guide other beginners along. Your non-expert perspective will make you a great teacher!
You can draw on that friendly community to help you present, too! Share a presentation with somebody more or less experienced to make an expert-beginner duet, or have a friend cover an aspect of your topic that they know better. Get a friend to review your talk as you develop it. Shop your ideas around your local Python usergroup and see what suggestions they have.
PyOhio is not all about talks, of course (for me, the talks are kind of the excuse we use to get together and do the other stuff.) Also consider proposing something like
Thank you, and spread the word!
For my newest ipython-sql trick, I needed to compare some queries run across different databases. How hard would it be to get side-by-side results into tidy IPython Notebook output?
Not hard at all, it turns out, if you're willing to violate basic principles of human decency.
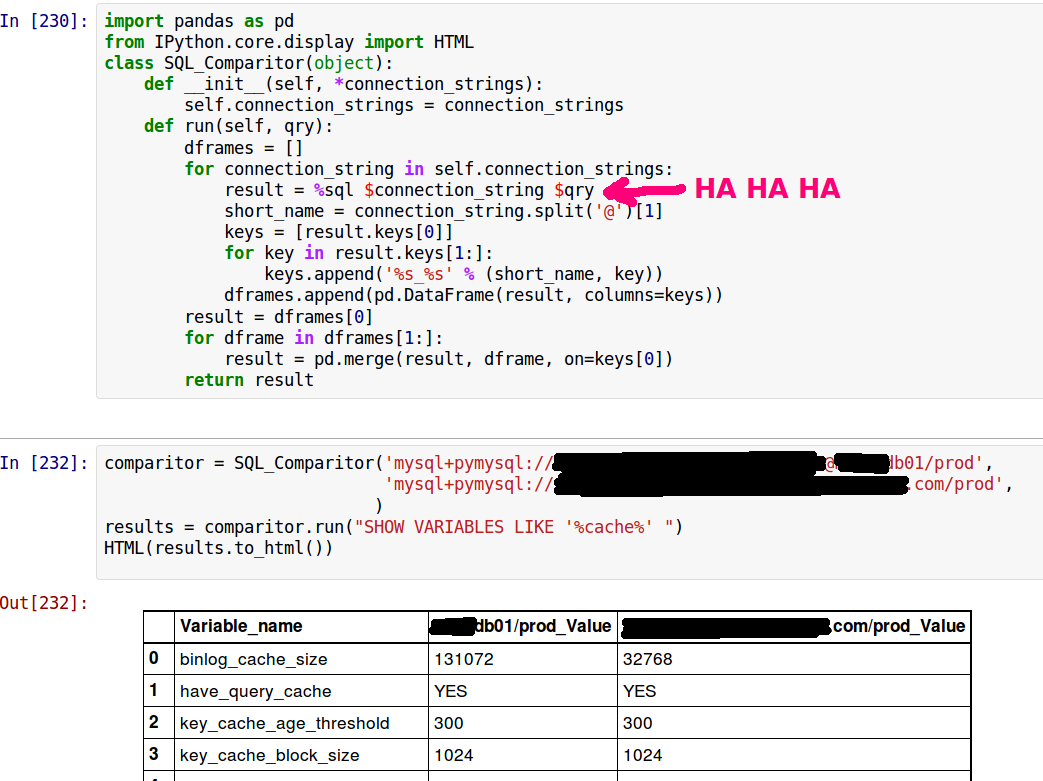
That's an itty-bitty image, so here's the crazy part:
class SQL_Comparitor(object):
def __init__(self, *connection_strings):
self.connection_strings = connection_strings
def run(self, qry):
dframes = []
for connection_string in self.connection_strings:
result = %sql $connection_string $qry
Did you catch that? I used %sql magic and IPython variable substitution inside an instance method. It feels so wrong! But it works! Provided you're running within IPython, of course; normal Python will not under any circumstances run an unholy perlish abomination like this. I'm just really amazed that we can use IPython tricks inside class definitions, but it's real.
Since the result is a Pandas DataFrame, it's easy to apply transformations. For instance, say you only want the rows where the values are different:
diff = results[results['svr1/db1_Value'] != results['svr2/db2_Value']]
HTML(diff.to_html())
I'm not sure how to distribute this class, since it's small and it's not actually valid Python, just valid IPython. For now I've made a gist (and its nbviewer version).